

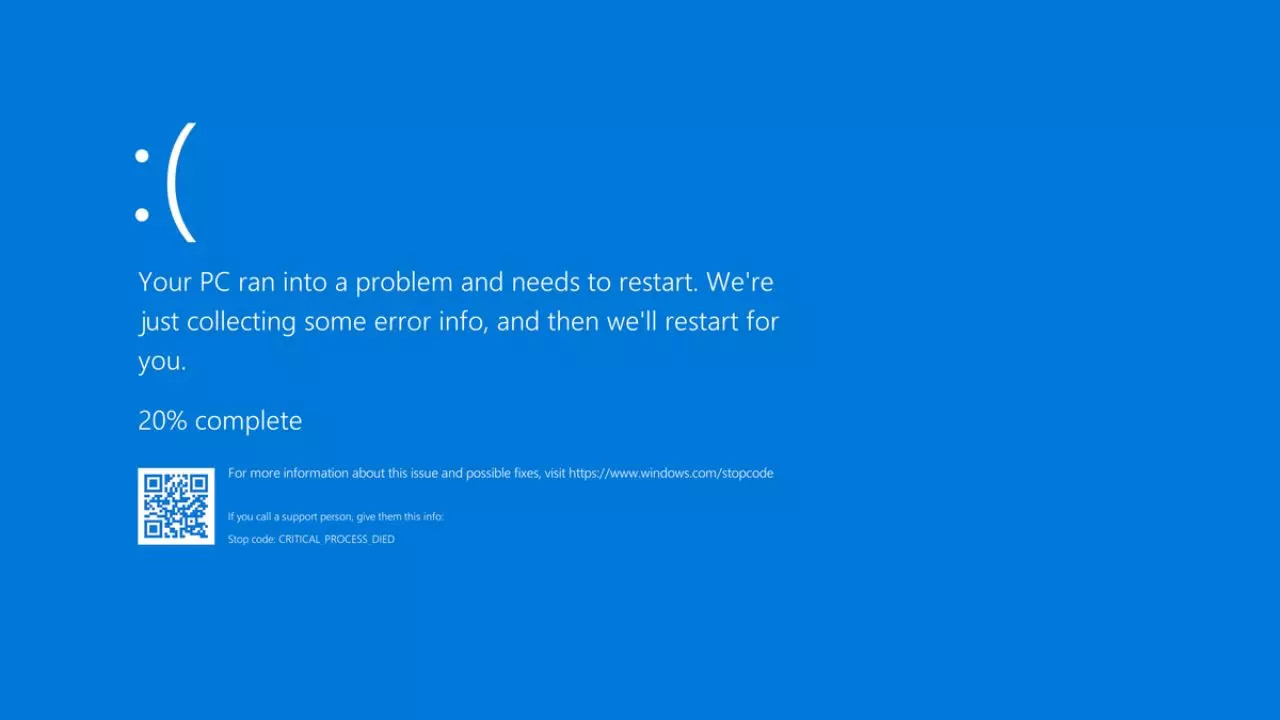
This isn’t a gloat post. In fact, I was completely oblivious to this massive outage until I tried to check my bank balance and it wouldn’t log in.
Apparently Visa Paywave, banks, some TV networks, EFTPOS, etc. have gone down. Flights have had to be cancelled as some airlines systems have also gone down. Gas stations and public transport systems inoperable. As well as numerous Windows systems and Microsoft services affected. (At least according to one of my local MSMs.)
Seems insane to me that one company’s messed up update could cause so much global disruption and so many systems gone down :/ This is exactly why centralisation of services and large corporations gobbling up smaller companies and becoming behemoth services is so dangerous.
deleted by creator
It’s not a Microsoft problem
It’s a world-depending-on-a-few-large-companies problem
I would be too, except Firefox just started crashing on Wayland all the morning D;
New Nvidia driver?
Yes but I upgraded to 555 at least a week or two ago and it started crashing a couple of days ago, I think there’s an issue with explicit sync
explicit sync is used, but no acquire point is set
If you Google this you’ll find various bug reports
deleted by creator
I love how everyone understands the issue wrong. It’s not about being on Windows or Linux. It’s about the ecosystem that is common place and people are used to on Windows or Linux. On windows it’s accepted that every stupid anticheat can drop its filthy paws into ring 0 and normies don’t mind. Linux has a fostered a less clueless community, but ultimately it’s a reminder to keep vigilant and strive for pure and well documented open source with the correct permissions.
BSODs won’t come from userspace software
Crowdstrike does have linux and mac version. Not sure who runs it
I deployed it for my last employer on our linux environment. My buddies who still work there said Linux was fine while they had to help the windows Admins fix their hosts.
That’s precisely why I didn’t blame windows in my post, but the windows-consumer mentality of “yeah install with privileges, shove genshin impact into ring 0 why not”
Linux can have the same issue. We have to keep the culture on our side here vigilant and pure near the kernel.
While that is true, it makes sense for antivirus/edr software to run in kernelspace. This is a fuck-up of a giant company that sells very expensive software. I wholeheartedly agree with your sentiment, but I mostly see this as a cautionary tale against putting excessive trust and power in the hands of one organization/company.
Imagine if this was actually malicious instead of the product of incompetence, and the update instead ran ransomware.
If it was malicious it wouldn’t have had the reach a trusted platform would. That is what made the xz exploit so scary was the reach and the malicious attempt.
I like open source software but that’s one big benefit of proprietary software. Not all proprietary software is bad. We should recognize the ones doing their best to avoid anti consumer practices and genuinely try to serve their customers needs to the best of their abilities.
Is there an easy way to silence every fuckdamn sanctimonious linux cultist from my lemmy experience?
Secondly, this update fucked linux just as bad as windows, but keep huffing your own farts. You seem to like it.
username… checks out?
Oh you really have no fucking clue. It’s medical and no treatment has worked for more than a few weeks. it’s only a matter of time before I am banned. Now imagine living with that for 4+ decades and being the butt of every thread’s joke.
A real shame that can’t be considered medical discrimination.
That sounds exhausting. I hope you find peace, one day.
I’d unsubscribe from !linux@lemmy.ml for a start.
I’m pretty sure this update didn’t get pushed to linux endpoints, but sure, linux machines running the CrowdStrike driver are probably vulnerable to panicking on malformed config files. There are a lot of weirdos claiming this is a uniquely Windows issue.
Thanks for the tip, so glad Lemmy makes it easy to block communities.
Also: It seems everyone is claiming it didn’t affect Linux but as part of our corporate cleanup yesterday, I had 8 linux boxes I needed to drive to the office to throw a head on and reset their iDrac so sure maybe they all just happened to fail at the same time but in my 2 years on this site we’ve never had more than 1 down at a time ever, and never for the same reason. I’m not the tech head of the site by any means and it certainly could be unrelated, but people with significantly greater experience than me in my org chalked this up to Crowdstrike.
Hi there! Looks like you linked to a Lemmy community using a URL instead of its name, which doesn’t work well for people on different instances. Try fixing it like this: !linux@lemmy.ml
Microsoft should test all its products on its own computers, not on ours. Made an update, tested it and only then posted it online.
Microsoft has nothing to do with this. This is entirely on Crowdstrike.
I work in hospitality and our systems are completely down. No POS, no card processing, no reservations, we’re completely f’ked.
Our only saving grace is the fact that we are in a remote location and we have power outages frequently. So operating without a POS is semi-normal for us.
I’ve worked with POS systems my whole career and I still can’t help think Piece Of Shit whenever I see it
This is exactly why centralisation of services and large corporations gobbling up smaller companies and becoming behemoth services is so dangerous.
Its true, but otherside of same coin is that with too much solo implementation you lose benefits of economy of scale.
But indeed the world seems like a village today.
you lose benefits of economy of scale.
I think you mean - the shareholders enjoy the profits of scale.
When a company scales up, prices are rarely reduced. Users do get increased community support through common experiences especially when official channels are congested through events like today, but that’s about the only benefit the consumer sees.
Crowdstrike already killed some Linux machines. Let’s not pretend Windows is at fault here or Linux is magically better in this area. No one is immune from software that can run as a kernel module going bad.
Every system has its faults. And I’m still going to dogpile the system with the most faults. But hell Microsoft did buy GitHub, Halo, MineCraft, and a million other things they will probably find a way to buy Linux and ruin it for us just like they ruin everything else.
Let’s see, …we are somewhere in between Extend and Extinguish on the roadmap.
Edit: Case & Point, RIP RedHat & IBM and GitHub CoPilot, what a great idea. RIP Atom Editor and probably a million other things. Do we have a KilledByMicrosoft website yet? I hope people in the pharmacy could get their prescriptions or we might have to add peoples names to the list.
Also fyi Red Hat and IBM are still around and aren’t really a force for good anyway. Stop SIMPing for large companies.
Hilarious. I am sure that, out of principle, you have stopped using all the software that Red Hat contributes to your distribution.
If it is ok with you, I am not going to define my morality in terms of corporate interest. They are not my friends but I do not believe that shutting on their contributions does much for me either.
I am not shitting on their contributions. All I am saying is that as a large company they aren’t anymore my friend than Microsoft. Generally they still exist and make contributions. Microsoft didn’t kill them like the person I am replying to is insinuating.
None of this has to do with the current outage though.
I hope people in the pharmacy could get their prescriptions or we might have to add peoples names to the list.
Which isn’t Microsoft’s fault. Linux systems have also been taken down by Crowdstrike’s fuck ups in the recent past.
Microsoft has many faults and I’ll criticize them as I please. And if Linux is a culprit in a global outage someday I’ll contemplate criticizing them too.
This “Not Microsoft’s Fault” comes off as white knighting for Muh Billion Dolla Corporation.
Do we really need to SIMP for the company town.
Microsoft, Google, Apple, Amazon and others deserve every ounce of vitrol they earn through their shitty practices. Again I am criticizing them for being shitty not for the particulars of System X vs System Z but for the aftermath.
Sure you can criticize as much as you want but if you are wrong in your criticism it just damages all of your criticism over all.
In my opinion it is important to state facts not fiction. This was not Microsoft’s fault, no matter how much you hate Microsoft it still wasn’t there fault and saying that is was is incorrect and doesn’t solve the issue.
Well said, that’s one of the points I have been trying to get across.
Except they haven’t done anything shitty this time. What you are doing would be a bit like claiming the Nazis are responsible for micro plastics. Like yeah Nazis are shit but making false allegations is just giving their defenders something to throw in your face. It makes you, and everyone who is critical of Microsoft look dumb. How about you criticize the company that actually screwed up? They are also a multi-billion dollar company, yet you aren’t blaming them for something that is clearly their fault.
I get where you are coming from, but this event is pretty much entirely the fault of Crowdstrike and the countless organizations that trusted them. It’s definitely a show of how massive outages are more likely when things are overly centralized and proprietary, and managed by big, shitty, profit driven organizations. Since crowdstrike operates in kernel space, it doesn’t matter which operating system it’s on, it can break it if it does something stupid. In fact they managed to break some redhat machines not too long ago, and some Debian machines not long before that. It’s just the impact wasn’t as far reaching as this recent utter fuckup, just because fewer critical machines were affected, so we didn’t hear about those smaller fuckups in the news.
Yes, thank you, exactly. The centralized model has its benefits but it also can act as a single point of failure.
If I was going to analyze from an engineering perspective I would focus on when these inevitable events occur due to human error do we have adequate tools to roll back updates? Do we snapshot OS drives before updates? Is there adequate Safe Mode or Fallback Tools to diagnose which files are offending in order to allow the user to remove them.
In my view the windows user isn’t dignified to have the skills or intelligence needed to workaround a “setback” issue like the one yesterday.
It doesn’t help that NTFS is missing modern capabilities, or that there isn’t easy to use DIFF for the layman to understand which files were added to the filesystem that may be causing the breakage.
To be fair though even with those pot holes filled the entire design paradigm of Windows and a proprietary platform is part of the problem. Software is not broken up into package modules that can be assembled into a functioning system it is encumbered with “anti-piracy” boogie man where the software treats the user as an enemy and is designed to break.
Linux isn’t like that. I’ve cloned many distro drives and swapped them into new machines and with 1 or 2 tweaks they JustWork
I see many people on the net defending Microsoft as blameless for technical reasons.
My criticisms were that Microsoft just sucks as you interpreted correctly and offered a eloquent summary. Thank You.
Where I think the entire conversation should move is –
What are the design flaws that allowed this to happen?
“More Rust & Less C” I see some people suggest as this was allegedly a null pointer issue.
And is Windows Broken By Design? My opinion answer - Yes.
(Okay, and what to do about it before the next billion dollars is lost. I would think critical infrastructure should have a model similar to NixOS in immutability but that’s just my opinion.)
Windows does have a fallback mode called safe mode and that’s exactly what’s being used to fix this utter mess.
Package management isn’t going to save you from this as it didn’t save the Linux systems affected last time. It didn’t stop Arch Linux from failing to boot after a Grub update either.
Windows also has drive cloning tools, that isn’t unique to Linux.
NixOS isn’t immutable. It’s not an a/b root system and / isn’t read only. Rather it’s what’s known as reproducible. I am not convinced NixOS would make this any easier either given how simple the fix was. Funnily enough though tools exist called ansible and puppet for configuring systems in repeatable ways that apply to both other Linux systems, Windows systems, and even macOS.
There are like one or two valid points in this whole comment and the rest is pretty much falsehoods and misconceptions.
Edit: Forgot to mention tools exist to make Windows immutable as well. So that is an option.
Windows does have a fallback mode called safe mode and that’s exactly what’s being used to fix this utter mess.
The other fix was reboot your Windows computer at least 15 times.
Package management isn’t going to save you from this as it didn’t save the Linux systems affected last time. It didn’t stop Arch Linux from failing to boot after a Grub update either.
Not everyone was affected though :
How come not everyone was impacted?
Prior to the most recent version, grub only registered the fwsetup if detected support. If your machine detected support, you would have had the fwsetup command registered and the failure wouldn’t occur.
I’ve just spent the past 6 hours booting into safe mode and deleting crowd strike files on servers.
Can’t you automate it?
Since it has to happen in windows safe mode it seems to be very hard to automate the process. I haven’t seen a solution yet.
Sadly not. Windows doesn’t boot. You can boot it into safe mode with networking, at which point maybe with anaible we could login to delete the file but since it’s still manual work to get windows into safe mode there’s not much point
It is theoretically automatable, but on bare metal it requires having hardware that’s not normally just sitting in every data centre, so it would still require someone to go and plug something into each machine.
On VMs it’s more feasible, but on those VMs most people are probably just mounting the disk images and deleting the bad file to begin with.
I guess it depends on numbers too. We had 200 to work on. If you’re talking hundreds more than looking at automation would be a better solution. In our scenario it was just easier to throw engineers at it. I honestly thought at first this was my weekend gone but we got through them easily in the end.
Feel you there. 4 hours here. All of them cloud instances whereby getting acces to the actual console isn’t as easy as it should be, and trying to hit F8 to get the menu to get into safe mode can take a very long time.
Ha! Yes. Same issue. Clicking Reset in vSphere and then quickly switching tabs to hold down F8 has been a ball ache to say the least!
What I usually do is set next boot to BIOS so I have time to get into the console and do whatever.
Also instead of using a browser, I prefer to connect vmware Workstation to vCenter so all the consoles insta open in their own tabs in the workspace.
Just go into settings and add a boot delay, then set it back when you’re done.
From my understanding, they have some ring 0 thing that fucked up. Could that not in theory happen on our beloved Linux systems? Or does the kernel generally not give that option?
My brother in Christ, I’ve borked Linux systems with a misplaced text file =D
So have I, multiple times, yeah
♬This is me ♬ - https://fosstodon.org/@vanillaos/112749170589287081
Most people are completely oblivious because it only affects people using crowdstrike, which practically excludes general consumers.
I just had an Amazon package delayed for a week it says. It doesn’t name names but…
A small number of deliveries may arrive a day later than anticipated due to a third-party technology outage.
Same here. I was totally busy writing software in a new language and a new framework, and had a gazillion tabs on Google and stackexchange open. I didn’t notice any network issues until I was on my way home, and the windows f-up was the one big thing in the radio news. Looks like Windows admins will have a busy weekend.
Only if they manage Crowdstrike systems, thankfully.
For reference, this was the article I first read about this on: https://www.nzherald.co.nz/nz/bank-problems-reports-bnz-asb-kiwibank-anz-visa-paywave-services-down/R2EY42QKQBALXNF33G5PA6U3TQ/











